Hengli Li, Song-Chun Zhu , Zilong Zheng
Peking University, BIGAI
Code | arXiv

Pragmatic reasoning plays a pivotal role in deciphering implicit meanings that frequently arise in real-life conversations and is essential for the development of communicative social agents. In this paper, we introduce a novel challenge, DiPlomat, aiming at benchmarking machines’ capabilities on pragmatic reasoning and situated conversational understanding. Compared with previous works that treat different figurative expressions (e.g. metaphor, sarcasm) as individual tasks, DiPlomat provides a cohesive framework towards general pragmatic understanding. Our dataset is created through the utilization of Amazon Mechanical Turk ( AMT ), resulting in a total of 4, 177 multi-turn dialogues. In conjunction with the dataset, we propose two tasks, Pragmatic Identification and Reasoning (PIR) and Conversational Question Answering (CQA). Experimental results with state-of-the-art (SOTA) neural architectures reveal several significant findings: 1) large language models (LLMs) exhibit poor performance in tackling this subjective domain; 2) comprehensive comprehension of context emerges as a critical factor for establishing benign human-machine interactions; 3) current models defect in the application of pragmatic reasoning. As a result, we call on more attention to improve the ability of context understanding, reasoning, and implied meaning modeling.
Diplomat Dataset
The Diplomat dataset owns 4,177 data and covers a vocabulary of 48,900 words. More than that, human-annotated answers reach an amount of 6,494, hold a vocabulary size of 20,000, and cover 5 types of reasoning. Along with the dataset, we propose two tasks: Pragmatic Identification and Reasoning (PIR) and Conversational Question Answering. The latter possesses 19,482 questions concerning the content of collected dialogues and the answers to the questions are written by humans. We benchmark those tasks with current SOTA models. Their performances are under our expectations. The best model achieves less than a 0.70 accuracy score in the first task, and none of the models achieve more than a 0.30 accuracy score for the second. Regarding the experimental results provided, the significance of pragmatic reasoning speaks for itself, therefore we hope to provide the community with a dataset for better studying the problem of pragmatic reasoning and give some insights into the current situation of generative language modeling.
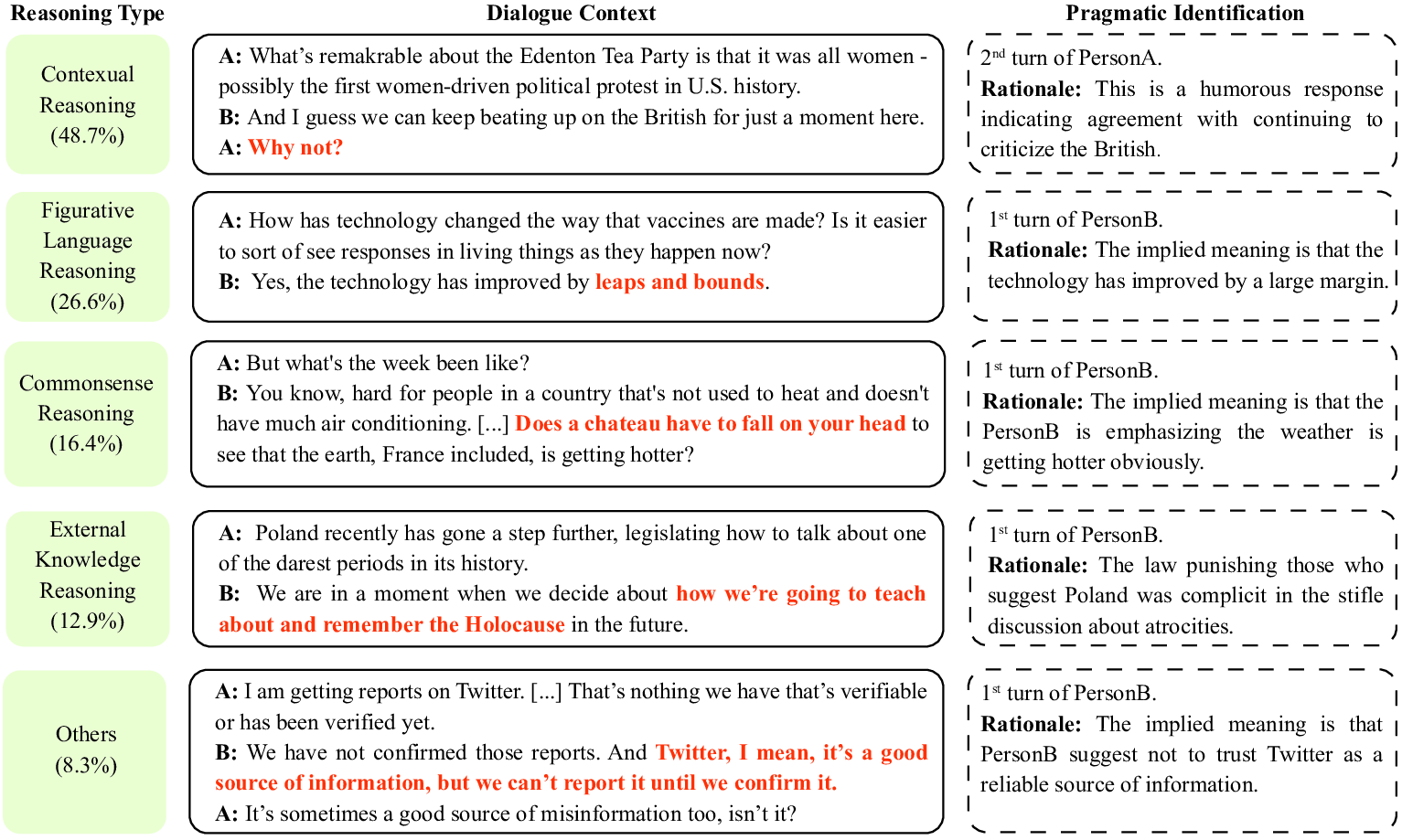
Tasks
We propose 2 tasks: Pragmatic Identification and Reasoning (PIR) and Conversational Question Answering (CQA).
| Task | Direct Testing | Ability | Description |
|---|---|---|---|
| PIR | Yes | Pragmatic Awareness, Pragmatic Reasoning | Models are provided with dialogues and are required to identify turns whose actual meanings deviate from their literal interpretations, commonly referred to as pragmatic turns. If their selections are accurate, a set of rationales is presented and they are expected to choose the most plausible reason for each pragmatic turn. |
| CQA | No | Pragmatic Awareness, Pragmatic Reasoning, Application | Models are provided with dialogue and a question that is designed for the pragmatic turn. They are expected to choose an answer from the choice pool to the question |
Paper
DiPlomat: A Dialogue Dataset for Situated Pragmatic Reasoning (Paper link)
Hengli Li, Song-Chun Zhu, Zilong Zheng
arXiv, 2023
Download
Our dataset is distributed under the CC BY-NC-SA (Attribution-NonCommercial-ShareAlike) license. You can download our dataset from Link here or from huggingface.
For data from google drive, the following code is recommended to use for loading the dataset, while the Huggingface transformers package is needed.
from datasets import load_from_disk
dataset = load_from_disk(f"{dataset_directory_name}")
Citation
@inproceedings{li2023diplomat,
title={DiPlomat: A Dialogue Dataset for Situated Pragmatic Reasoning},
author={Hengli Li and Song-Chun Zhu and Zilong Zheng},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2023}
}
Contact
Please contact lihengli@stu.pku.edu.cn for questions about the Diplomat dataset.\